Pandas的知识与实践
 爱校码
爱校码
致力于少儿编程与软件工程的信息分享
Pandas与NumPy的主要区别在于:NumPy中的ndarray只能进行数值类型的数据处理,而Pandas是基于NumPy进一步封装的包,并且提供了计算接口,丰富并简化了Numpy的操作,使得Pandas既可以进行数值类型的数据处理,也可以进行非数值类型的数据统计与分析。
一、Pandas的安装和使用
Pandas的使用需要结合NumPy才行,所以Pandas安装前要先安装NumPy:
pip install numpy
pip install pandas
Pandas使用前,先将Pandas导入才能继续后续操作:
import pandas as pd
二、Pandas数据结构
Pandas非常适合许多不同类型的数据,具有异构类型列的表格数据,包含有序和无序时间序列数据,具有行和列标签的任意矩阵数据,以及观察/统计数据集的任何其他形式。实际上,数据根本不需要标记即可放入Pandas数据结构。那么Pandas的数据结构如何?主要有两种主要的数据结构,分别是Series(一维)和DataFrame(二维)。
2.1 Series
一维标记的均匀类型数组,类似于定长的有序字典,有Index和value。
它由一组数据和一组与数据相对应的数据标签(索引index)组成。这组数据和索引标签的基础都是一个一维ndarray数组。可将index索引理解为行索引。 Series的表现形式为:索引在左,数据在右。
根据列表生成Series:
>>> import pandas as pd
>>> list = ['a','b','c']
>>> sf = pd.Series(list)
>>> sf
0 a
1 b
2 c
dtype: object
>>> type(sf)
<class 'pandas.core.series.Series'>
>>> sf[1]
'b'
>>>
获取数据和索引:
>>> sf.index
RangeIndex(start=0, stop=3, step=1)
>>> for i in sf.index:
... print(i)
...
0
1
2
>>> sf.values
array(['a', 'b', 'c'], dtype=object)
>>> for v in sf.values:
... print(v)
...
a
b
c
>>>
预览数据:
>>> list1 = [1,2,3,4,5]
>>> index1 = ['a','b','c','d','e']
>>> sf1 = pd.Series(list1,index=index1)
>>> sf1
a 1
b 2
c 3
d 4
e 5
dtype: int64
>>> sf1['c']
3
>>> sf1.head(2)
a 1
b 2
dtype: int64
>>> sf1.tail(2)
d 4
e 5
dtype: int64
>>>
2.2 DataFrame
具有潜在不同类型列的常规二维标记、大小可变的表格结构。
DataFrame是一个类似表格的数据结构,索引包括列索引和行索引,包含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。DataFrame的每一行和每一列都是一个Series,这个Series的name属性为当前的行索引名/列索引名。
用列表生成DataFrame:
>>> list = [[1,2,3],[4,5,6],[7,8,9]]
>>> df = pd.DataFrame(list,columns=['a','b','c'])
>>> df
a b c
0 1 2 3
1 4 5 6
2 7 8 9
>>> type(df)
<class 'pandas.core.frame.DataFrame'>
>>>
用字典生成DataFrame:
>>> data = {'city':['Beijing', 'Shanghai', 'Tianjin', 'Shenzhen'],
... 'year':[2014, 2015, 2016, 2017],
... 'pop':[2.5, 2.3, 1.1, 0.9]}
>>> df1 = pd.DataFrame(data)
>>> df1
city pop year
0 Beijing 2.5 2014
1 Shanghai 2.3 2015
2 Tianjin 1.1 2016
3 Shenzhen 0.9 2017
>>>
生成一个指定列名的DataFrame:
>>> df2 = pd.DataFrame(data,columns=['city','year','pop','debt'])
>>> df2
city year pop debt
0 Beijing 2014 2.5 NaN
1 Shanghai 2015 2.3 NaN
2 Tianjin 2016 1.1 NaN
3 Shenzhen 2017 0.9 NaN
>>>
获取某列数据(是一个Series结构): DataFrame的单列数据为一个Series。DataFrame是一个带有标签的二维数组,每个标签相当于每一列的列名。
>>> df2['city'] # 以字典方式访问某一个key的值,使用对应的列名,实现单列数据访问
0 Beijing
1 Shanghai
2 Tianjin
3 Shenzhen
Name: city, dtype: object
>>> df2.year # 以属性的方式访问,实现单列数据的访问
0 2014
1 2015
2 2016
3 2017
Name: year, dtype: int64
>>>
根据索引取值、切片:
>>> df2.loc[0] # loc[行索引名称或条件表达式, 列索引名称]。内部传入行索引名称如果为一个区间,则前后均为闭区间。
city Beijing
year 2014
pop 2.5
debt NaN
Name: 0, dtype: object
>>> df2.loc[2]
city Tianjin
year 2016
pop 1.1
debt NaN
Name: 2, dtype: object
>>> df2.iloc[:,0:2] # iloc[行索引位置, 列索引位置]。内部传入的行索引位置或列索引位置为区间时,则为前闭后开区间。
city year
0 Beijing 2014
1 Shanghai 2015
2 Tianjin 2016
3 Shenzhen 2017
>>>
添加列、给列赋值,如果没有值,填充NaN值:
>>> df2['debt'] = 12
>>> df2
city year pop debt
0 Beijing 2014 2.5 12
1 Shanghai 2015 2.3 12
2 Tianjin 2016 1.1 12
3 Shenzhen 2017 0.9 12
>>> df2['y_a_p'] = df2['year']+df2['pop']
>>> df2['abb']=df2['city'].str[:2]
>>> df2['abb1']=df2['city'].str.split('j').str[0]
>>> df2
city year pop debt y_a_p abb abb1
0 Beijing 2014 2.5 12 2016.5 Be Bei
1 Shanghai 2015 2.3 12 2017.3 Sh Shanghai
2 Tianjin 2016 1.1 12 2017.1 Ti Tian
3 Shenzhen 2017 0.9 12 2017.9 Sh Shenzhen
>>> #################################################
>>> def sam_lambda(x):
... if len(x)>=8:
... return x[-3:]
... else:
... return x
...
>>> df2['abb2'] = df2['city'].apply(lambda x: sam_lambda(x))
>>> df2
city year pop debt y_a_p abb abb1 abb2
0 Beijing 2014 2.5 12 2016.5 Be Bei Beijing
1 Shanghai 2015 2.3 12 2017.3 Sh Shanghai hai
2 Tianjin 2016 1.1 12 2017.1 Ti Tian Tianjin
3 Shenzhen 2017 0.9 12 2017.9 Sh Shenzhen hen
>>> #################################################
>>> val = pd.Series([-1.2, -1.5, -1.7], index = [0, 1, 3])
>>> df2['debt'] = val
>>> df2
city year pop debt y_a_p abb abb1 abb2
0 Beijing 2014 2.5 -1.2 2016.5 Be Bei Beijing
1 Shanghai 2015 2.3 -1.5 2017.3 Sh Shanghai hai
2 Tianjin 2016 1.1 NaN 2017.1 Ti Tian Tianjin
3 Shenzhen 2017 0.9 -1.7 2017.9 Sh Shenzhen hen
>>>
删除列:
>>> del df2['abb']
>>> del df2['abb1']
>>> del df2['abb2']
>>> df2
city year pop debt y_a_p
0 Beijing 2014 2.5 -1.2 2016.5
1 Shanghai 2015 2.3 -1.5 2017.3
2 Tianjin 2016 1.1 NaN 2017.1
3 Shenzhen 2017 0.9 -1.7 2017.9
>>>
数据清洗:
>>> df2.loc[4]=pd.Series(['Shenzhen',2017,0.9,-1.7,2017.9],index=df2.columns)
>>> df2
city year pop debt y_a_p
0 Beijing 2014 2.5 -1.2 2016.5
1 Shanghai 2015 2.3 -1.5 2017.3
2 Tianjin 2016 1.1 NaN 2017.1
3 Shenzhen 2017 0.9 -1.7 2017.9
4 Shenzhen 2017 0.9 -1.7 2017.9
>>> df2 = df2.dropna() # 去除空数据
>>> df2
city year pop debt y_a_p
0 Beijing 2014 2.5 -1.2 2016.5
1 Shanghai 2015 2.3 -1.5 2017.3
3 Shenzhen 2017 0.9 -1.7 2017.9
4 Shenzhen 2017 0.9 -1.7 2017.9
>>> >>> df2 = df2.drop_duplicates() # 去除重复数据
>>> df2
city year pop debt y_a_p
0 Beijing 2014 2.5 -1.2 2016.5
1 Shanghai 2015 2.3 -1.5 2017.3
3 Shenzhen 2017 0.9 -1.7 2017.9
>>>
条件选取数据:
>>> df2[df2['year']>=2015]
city year pop debt y_a_p
1 Shanghai 2015 2.3 -1.5 2017.3
3 Shenzhen 2017 0.9 -1.7 2017.9
>>>
分组(group by):
>>> df2.loc[4]=pd.Series(['Shenzhen',2018,1.9,-1.8,2018.9],index=df2.columns)
>>> df2
city year pop debt y_a_p
0 Beijing 2014 2.5 -1.2 2016.5
1 Shanghai 2015 2.3 -1.5 2017.3
3 Shenzhen 2017 0.9 -1.7 2017.9
4 Shenzhen 2018 1.9 -1.8 2018.9
>>> df2.groupby(by=['city']).mean()
year pop debt y_a_p
city
Beijing 2014.0 2.5 -1.20 2016.5
Shanghai 2015.0 2.3 -1.50 2017.3
Shenzhen 2017.5 1.4 -1.75 2018.4
>>>
2.3 数据表链接
在Pandas中DataFrame数据整合,需要使用链接操作。
行链接:
- pandas.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, copy=True)
concat方法相当于数据库中的全链接(union all),它不仅可以指定链接的方式(outer join或inner join),还可以指定按照某个轴进行链接。与数据库不同的是,它不会去重,但是可以使用drop_duplicates方法达到去重的效果。参数axis默认是0,指定为行。
>>> df1
city pop year
0 Beijing 2.5 2014
1 Shanghai 2.3 2015
2 Tianjin 1.1 2016
3 Shenzhen 0.9 2017
>>> df2
city year pop debt y_a_p
0 Beijing 2014 2.5 -1.2 2016.5
1 Shanghai 2015 2.3 -1.5 2017.3
3 Shenzhen 2017 0.9 -1.7 2017.9
4 Shenzhen 2018 1.9 -1.8 2018.9
>>> df3 = pd.concat([df1,df2]) # 行链接--concat
>>> df3
city debt pop y_a_p year
0 Beijing NaN 2.5 NaN 2014
1 Shanghai NaN 2.3 NaN 2015
2 Tianjin NaN 1.1 NaN 2016
3 Shenzhen NaN 0.9 NaN 2017
0 Beijing -1.2 2.5 2016.5 2014
1 Shanghai -1.5 2.3 2017.3 2015
3 Shenzhen -1.7 0.9 2017.9 2017
4 Shenzhen -1.8 1.9 2018.9 2018
>>>
列链接:
- pandas.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=True, suffixes=('_x', '_y'), copy=True, indicator=False)
使用数据库样式的链接合并DataFrame或命名的Series对象。
链接在列或索引上完成。 如果在列上链接列,则DataFrame索引将被忽略。 否则,如果在索引上链接索引或在一个或多个列上建立索引,则将传递索引。
>>> data = {'city':['Beijing', 'Shanghai', 'Tianjin', 'Shenzhen'],
... 'area':[320, 350, 240, 220],
... 'post':['10', '20', '11', '22']}
>>> df4 = pd.DataFrame(data)
>>> df4
area city post
0 320 Beijing 10
1 350 Shanghai 20
2 240 Tianjin 11
3 220 Shenzhen 22
>>> df1
city pop year
0 Beijing 2.5 2014
1 Shanghai 2.3 2015
2 Tianjin 1.1 2016
3 Shenzhen 0.9 2017
>>> df5 = pd.merge(df1,df4,on='city') # 列链接--merge
>>> df5
city pop year area post
0 Beijing 2.5 2014 320 10
1 Shanghai 2.3 2015 350 20
2 Tianjin 1.1 2016 240 11
3 Shenzhen 0.9 2017 220 22
>>>
索引合并:
- pandas.DataFrame.join(self, other, on=None, how='left', lsuffix='', rsuffix='', sort=False)
在索引或键列上将列与其他DataFrame链接起来。 通过传递一个列表,一次有效地通过索引链接多个DataFrame对象。
>>> df1
city pop year
0 Beijing 2.5 2014
1 Shanghai 2.3 2015
2 Tianjin 1.1 2016
3 Shenzhen 0.9 2017
>>> df2
city year pop debt y_a_p
0 Beijing 2014 2.5 -1.2 2016.5
1 Shanghai 2015 2.3 -1.5 2017.3
3 Shenzhen 2017 0.9 -1.7 2017.9
4 Shenzhen 2018 1.9 -1.8 2018.9
>>> df1.join(df2, lsuffix='_caller', rsuffix='_other')
city_caller pop_caller year_caller city_other year_other pop_other debt y_a_p
0 Beijing 2.5 2014 Beijing 2014.0 2.5 -1.2 2016.5
1 Shanghai 2.3 2015 Shanghai 2015.0 2.3 -1.5 2017.3
2 Tianjin 1.1 2016 NaN NaN NaN NaN NaN
3 Shenzhen 0.9 2017 Shenzhen 2017.0 0.9 -1.7 2017.9
>>>
2.4 DataFrame的导入和导出
CSV数据:
- pd.read_csv(filepath_or_buffer,header,parse_dates,index_col)
将逗号分隔值(csv)文件读取到DataFrame中。
./abc.csv 文件内容:
a,b,c,d,message
1,2,3,4,zhangsan
5,6,7,8,lisi
9,10,11,12,wangmazi
>>> import pandas as pd
>>> df = pd.read_csv('abc.csv') # 打开后默认添加索引(index)为从0自增长,列(columns)默认采用第一行数据
>>> df
a b c d message
0 1 2 3 4 zhangsan
1 5 6 7 8 lisi
2 9 10 11 12 wangmazi
>>> df1 = pd.read_csv('abc.csv', header=None) # header参数指定列(columns)采用为从0自增长的数
>>> df1
0 1 2 3 4
0 a b c d message
1 1 2 3 4 zhangsan
2 5 6 7 8 lisi
3 9 10 11 12 wangmazi
>>> df2 = pd.read_csv('abc.csv', names=['first','second','third','fourth']) # 用names参数指定列(columns)的值
>>> df2
first second third fourth
a b c d message
1 2 3 4 zhangsan
5 6 7 8 lisi
9 10 11 12 wangmazi
>>> df3 = pd.read_csv('abc.csv', index_col='message') # 用index_col参数指定的列的首元素,使得该列作为索引index
>>> df3
a b c d
message
zhangsan 1 2 3 4
lisi 5 6 7 8
wangmazi 9 10 11 12
>>>
- pandas.DataFrame.to_csv(path_or_buf,index,header)
将对象写入逗号分隔值(csv)文件。
>>> df.head(2).to_csv('abc.csv') # 其中head(2)表示将前两行写入文件
>>> ''' 写入的文件内容:
... ,a,b,c,d,message
... 0,1,2,3,4,zhangsan
... 1,5,6,7,8,lisi
... '''
>>> df = pd.read_csv('abc.csv')
>>> df
Unnamed: 0 a b c d message
0 0 1 2 3 4 zhangsan
1 1 5 6 7 8 lisi
>>> df1.head(2).to_csv('abc.csv',index=False,header=False) # 参数index与header默认为True,在此表示把索引(index)和列头(columns)都弃掉
>>> ''' 写入文件的内容:
... a,b,c,d,message
... 1,2,3,4,zhangsan
... '''
>>> df1 = pd.read_csv('abc.csv')
>>> df1
a b c d message
0 1 2 3 4 zhangsan
>>>
三、Pandas绘图
Pandas实现的绘图功能基于matplotlib的API,Matplotlib是一个Python的 二维(2D)绘图库,其可以在各种平台及交互式环境生成具有出版品质的图形。在使用Pandas绘图之前,需要安装matplotlib库包:
pip install matplotlib
matplotlib的pyplot模块提供了绘图界面,先将其导入:
import matplotlib.pyplot as plt
使用pyplot模块的plot函数来绘图: 先导入模块pyplot,然后使用该模块的plot函数绘制折线图,接着调用该模块的相关函数来调整、设置图表的标题、横纵标签、刻度标记内容或大小。
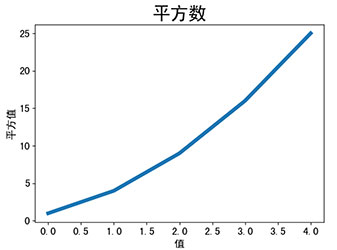
>>> import matplotlib.pyplot as plt
>>> plt.rcParams['font.sans-serif'] = 'SimHei' # 设置使得中文正常显示
>>> squares = [1, 4, 9, 16, 25]
>>> plt.plot(squares, linewidth=5) # 指定一个列表当作是Y参数,列表的索引值为X参数从0开始。设置线宽为5
[<matplotlib.lines.Line2D object at 0x11e313550>]
>>> plt.title(u'平方数', fontsize=24) # 指定标题,并设置标题字体大小
Text(0.5,1,'平方数')
>>> plt.xlabel(u'值', fontsize=14) # 指定X坐标轴的标签,并设置标签字体大小
Text(0.5,0,'值')
>>> plt.ylabel(u'平方值', fontsize=14) # 指定Y坐标轴的标签,并设置标签字体大小
Text(0,0.5,'平方值')
>>> plt.tick_params(axis='both', labelsize=14) # 参数axis值为both,代表要设置横纵的刻度标记,标记大小为14
>>> plt.show() # 打开matplotlib查看器,并显示绘制的图形
在Pandas中,pandas.Series.plot(self, *args, **kwargs)和pandas.DataFrame.plot(self, *args, **kwargs)上面使用plot方法进行绘图,只是围绕着matplotlib.pyplot.plot(*args, **kwargs)方法的简单封装。
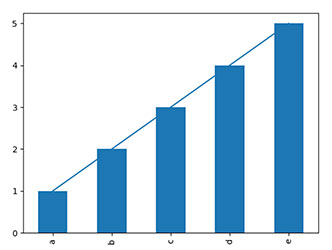
>>> import matplotlib.pyplot as plt
>>> import pandas as pd
>>> list1 = [1,2,3,4,5]
>>> index1 = ['a','b','c','d','e']
>>> sf1 = pd.Series(list1,index=index1)
>>> sf1.plot(kind='line')
<matplotlib.axes._subplots.AxesSubplot object at 0x112e74f98>
>>> sf1.plot(kind='bar')
<matplotlib.axes._subplots.AxesSubplot object at 0x112e74f98>
>>> plt.show()
博文最后更新时间: